機械学習の世界に足を踏み入れたことがあるなら、**scikit-learn**の名前を耳にしたことがあるでしょう。私たちがデータを解析し、モデルを構築する際に欠かせないライブラリです。シンプルで使いやすいインターフェースを持ちながら、強力な機能を提供するこのツールは、初心者からプロフェッショナルまで幅広いユーザーに支持されています。
scikitlearnとは
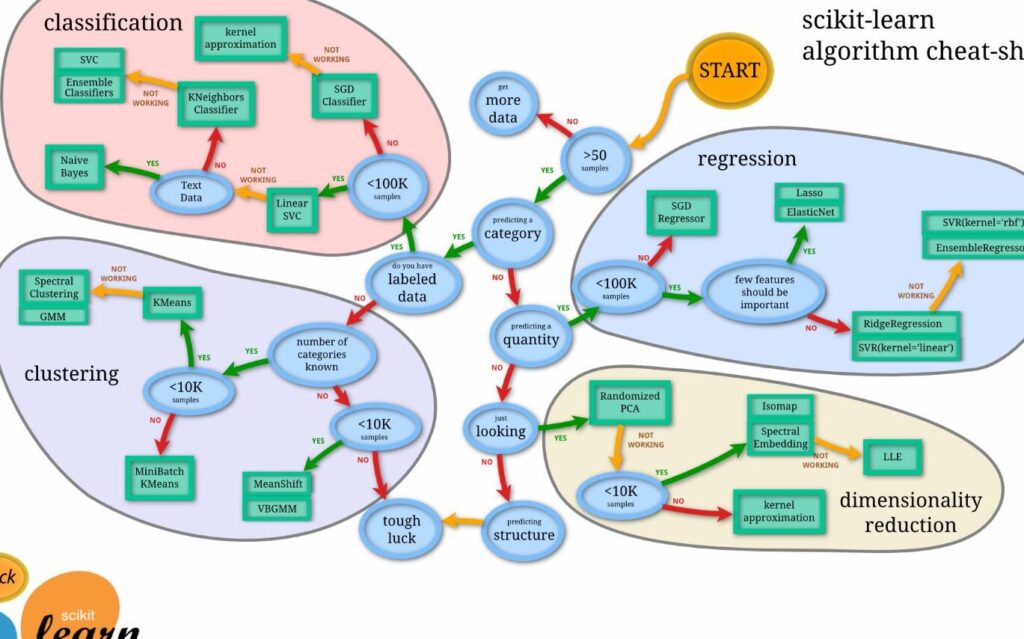
scikit-learnは、機械学習のライブラリであり、データ解析やモデル構築において広く使用されています。使いやすさや強力な機能で、多くのプロフェッショナルや初心者に支持されています。
scikitlearnの概要
scikit-learnは、Pythonで書かれたオープンソースのライブラリです。このライブラリは、機械学習アルゴリズムを迅速かつ効果的に実装するためのツールを提供しています。例えば、分類、回帰、クラスタリングといった多様なタスクを簡単に実行可能です。標準的なデータセットや豊富なドキュメントも提供されており、ユーザーはスムーズに学習を進められます。
主な機能
scikit-learnの主な機能には以下のようなものがあります。
- 分類:データを異なるカテゴリに分類するためのアルゴリズムを提供します。例えば、ロジスティック回帰やサポートベクターマシンなどがあります。
- 回帰:数値データの予測モデルを構築する機能があります。住宅価格の予測などに利用される線形回帰が含まれます。
- クラスタリング:似たようなデータをグループ分けする技術です。K-means法や階層クラスタリングなどがあります。
- 次元削減:データの特徴を減少させ、解析を容易にする技術が提供されます。主成分分析(PCA)が代表的です。
- モデル選択:異なるモデルを比較し、最適なものを選ぶための工具があります。交差検証やグリッドサーチなどが利用できます。
scikitlearnのインストール方法
scikit-learnのインストールは簡単です。以下の手順を順を追って実行して、環境を整えましょう。
環境設定
scikit-learnを使用するには、Pythonとpipが必要です。Pythonは公式サイトからダウンロード可能で、pipはPythonのパッケージ管理ツールです。以下の手順で環境を準備します。
- Pythonをインストールする。 最新版を公式サイトからダウンロードし、インストールを行います。
- pipを確認する。 コマンドラインまたはターミナルで「pip –version」と入力して、インストールが成功しているか確認します。
- 仮想環境を作成する。 「python -m venv myenv」と入力し、myenvという名前の仮想環境を作成します。
- 仮想環境をアクティベートする。 Windowsでは「myenvScriptsactivate」、macOS/Linuxでは「source myenv/bin/activate」と入力します。
インストール手順
環境が整ったら、scikit-learnのインストールに進みます。こちらも簡単です。
- pipでscikit-learnをインストールする。 コマンドラインで「pip install scikit-learn」と入力します。
- インストール状況を確認する。 「pip show scikit-learn」と入力して、正しくインストールされたか確認します。
scikitlearnの主要な機能
scikit-learnは機械学習の実装に特化した多くの機能を備えています。異なる分析やモデル構築のタスクに対して、強力で使いやすいライブラリです。以下に、scikit-learnの主な機能を詳しく見ていきます。
データ前処理
データ前処理は、機械学習プロジェクトにおいて不可欠です。以下のステップでデータを整えます。
- データを収集します。
- データのクレンジングを行い、欠損値や外れ値を処理します。
- 特徴量を選択または生成します。
- データを標準化または正規化します。
- データをトレーニングセットとテストセットに分割します。
このプロセスにより、モデルの性能を最大限に引き出すためのクリーンで信頼性の高いデータが得られます。
モデル構築
モデル構築においては、多様なるアルゴリズムから選択できます。具体的には、以下の手順でモデルを構築します。
- 問題に適したアルゴリズムを選択します。
- モデルをインスタンス化します。
- トレーニングデータを使ってモデルをトレーニングします。
- モデルのハイパーパラメータを調整します。
- トレーニング後のモデルをテストデータで評価します。
これにより、データに基づいた予測や分類が可能になります。
モデル評価
モデル評価は、性能を確認する重要なステップです。評価手段は次の通りです。
- 評価指標を選定します(例:精度、再現率、F1スコア)。
- モデルをテストデータで適用します。
- 実際の値と予測値を比較します。
- 評価指標を計算し、モデルの性能を分析します。
- 必要に応じてモデルを改善します。
scikitlearnの利点
scikitlearnの利点は多岐にわたります。使いやすさと強力な機能を兼ね備えているため、データサイエンティストやエンジニアにとって非常に価値のあるツールとなっています。ここでは主な利点を紹介します。
使いやすさ
scikitlearnはシンプルなインターフェースを持ち、複雑な操作なしで機械学習のタスクを実行可能です。以下の点が特に利用しやすさを際立たせます。
- 直感的なAPI: コードが短く、機械学習のモデルを簡単に定義・実行できます。
- 一貫性: 多くのアルゴリズムが同じ方法でアクセスできるため、学ぶのが容易です。
- 豊富なドキュメント: 公式のガイドやチュートリアルが充実しており、自己学習をサポートします。
- スムーズなデータ処理: データ前処理機能も備えているため、必要な準備が効率的に行えます。
コミュニティとサポート
scikitlearnは活発なコミュニティのおかげで、学習や問題解決が進めやすいです。具体的には次のような利点があります。
- フォーラム: ユーザーが情報を共有し、問題に対する解決策を討論できる場所が提供されています。
- GitHubのリポジトリ: バグレポートや新機能の提案が行われ、多くの貢献者が加わることで常に改善されています。
- ブログ記事やチュートリアル: 様々なメディアでの情報発信があり、新しい技術や機能がスムーズに学べます。
- イベントやワークショップ: 定期的に行われるセミナーやカンファレンスが、ユーザー同士の交流を促進します。
scikitlearnの使用例
scikit-learnの利用シーンは幅広く、さまざまなデータ解析や予測タスクで活用されます。以下に主要な使用例を示します。
クラシフィケーション
- データセットの準備
必要なライブラリをインポートします。具体的には、pandasやnumpyを使用します。その後、データを読み込み、必要な前処理を行います。
- 特徴量とラベルの選定
モデルに必要な特徴量と分類ラベルを選びます。この段階で、適切な特徴量の選定がモデルの性能に影響を与えます。
- データの分割
データセットを訓練用とテスト用に分けます。一般的には、訓練データを80%、テストデータを20%に分けることが推奨されます。
- モデルの選択
scikit-learn内の分類アルゴリズム(例:決定木、SVM)から、適切なモデルを選びます。
- モデルの訓練
選んだモデルを使って訓練データで調整します。ここで、モデルがデータに適応するように訓練します。
- 予測の実施
テストデータを用いてモデルの予測を行います。このステップで、モデルがどれだけ正確かを測定することができます。
- モデル評価
予測結果と実際のラベルを比較し、精度を計算します。必要に応じて、混同行列などを用いてモデルの性能を詳しく分析します。
リグレッション
- データセットの準備
分析に必要なライブラリをインポートし、データを読み込みます。具体的には、pandasやnumpyを活用します。
- 特徴量と目的変数の設定
モデルに使用する特徴量と目的変数(予測したい値)を設定します。この設定はモデルの結果に直接影響します。
- データの分割
データを訓練とテスト用に分けます。通常、80%を訓練、20%をテストとして使用します。
- モデルの選択
回帰問題に適したscikit-learnのアルゴリズム(例:線形回帰、リッジ回帰)を選びます。
- モデルの訓練
訓練データを使ってモデルを調整します。この段階で、モデルがデータに最適化されます。
- 予測の実行
テストデータを用いて、訓練したモデルで予測を行います。この結果でモデルの性能を確認します。
- モデルの評価
Conclusion
scikit-learnは機械学習の強力なパートナーです。私たちはこのライブラリを通じてデータ解析やモデル構築のプロセスをスムーズに進めることができます。直感的なAPIと豊富なドキュメントにより初心者でも簡単に始められます。
また活発なコミュニティのサポートも魅力の一つです。私たちが直面する問題に対して、さまざまなリソースが利用できるため、常に学び続けることが可能です。scikit-learnを活用して、より効果的な機械学習モデルを構築していきましょう。